Verifiable agentic environments for consumer and enterprise knowledge work.
An agent is only as good as what it trains on. We prepare complex, verifiable data for benchmarking, SFT and RL, at frontier difficulty.
Four environment types
How the agent perceives and acts, and the state each one is graded on.
The agent works entirely through an MCP server over seeded data. No screen, no DOM. Graded on what changed in the backend.
- Acts
- Calls real APIs through an MCP server
- Graded on
- Backend database state
The agent drives a working clone of a real web app and is graded on the resulting site state, not on what it claims it did.
- Acts
- Acts on the page through the browser
- Graded on
- Resulting site state
A vision-only agent on a real desktop, spanning several apps, files and the OS. Graded on the final machine state.
- Acts
- Drives mouse and keyboard
- Graded on
- Final machine state
GUI and tools in one environment. The agent decides which surface to use per step, and both write to the same shared store.
- Acts
- Chooses when to click and when to call
- Graded on
- Backend state
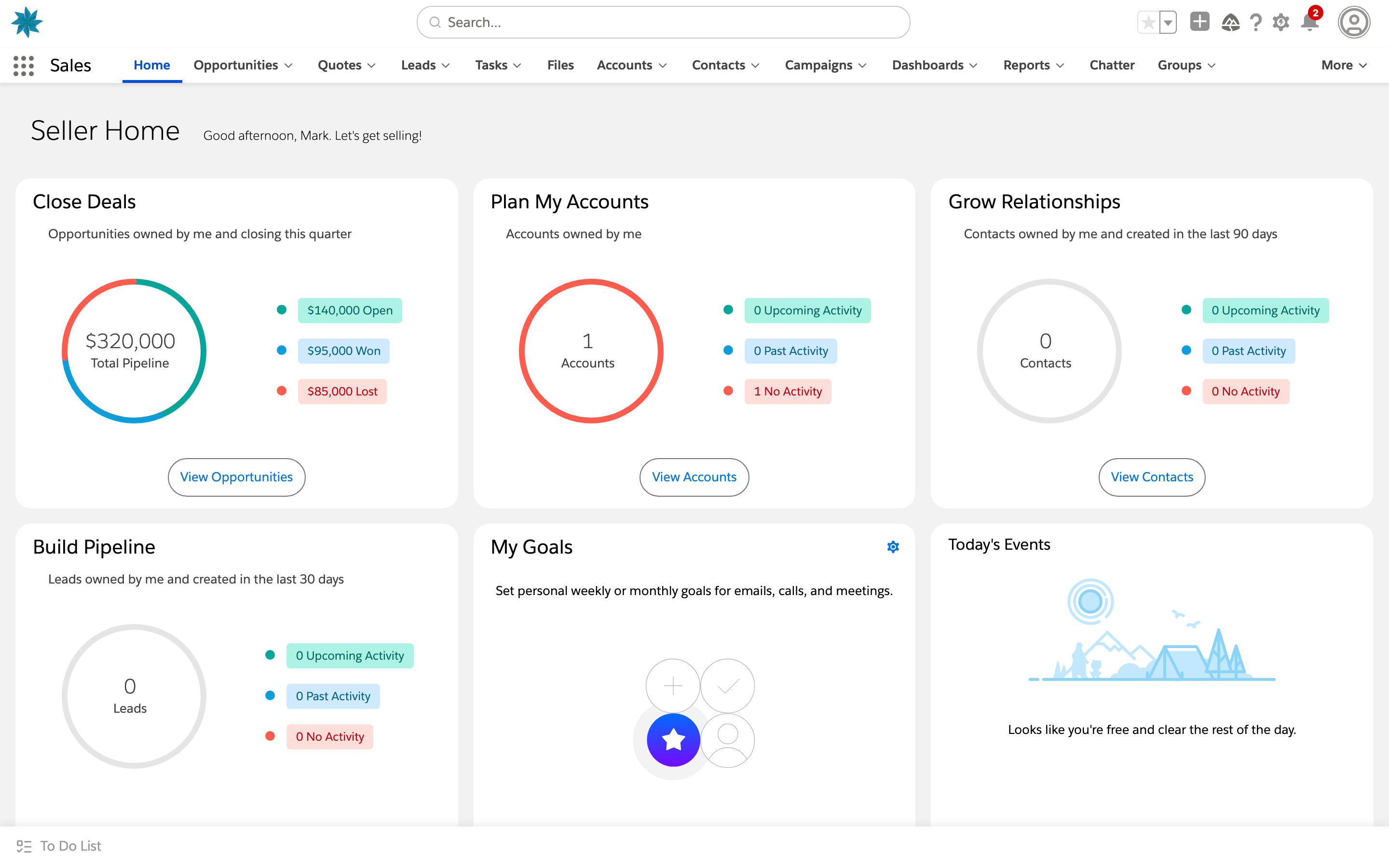
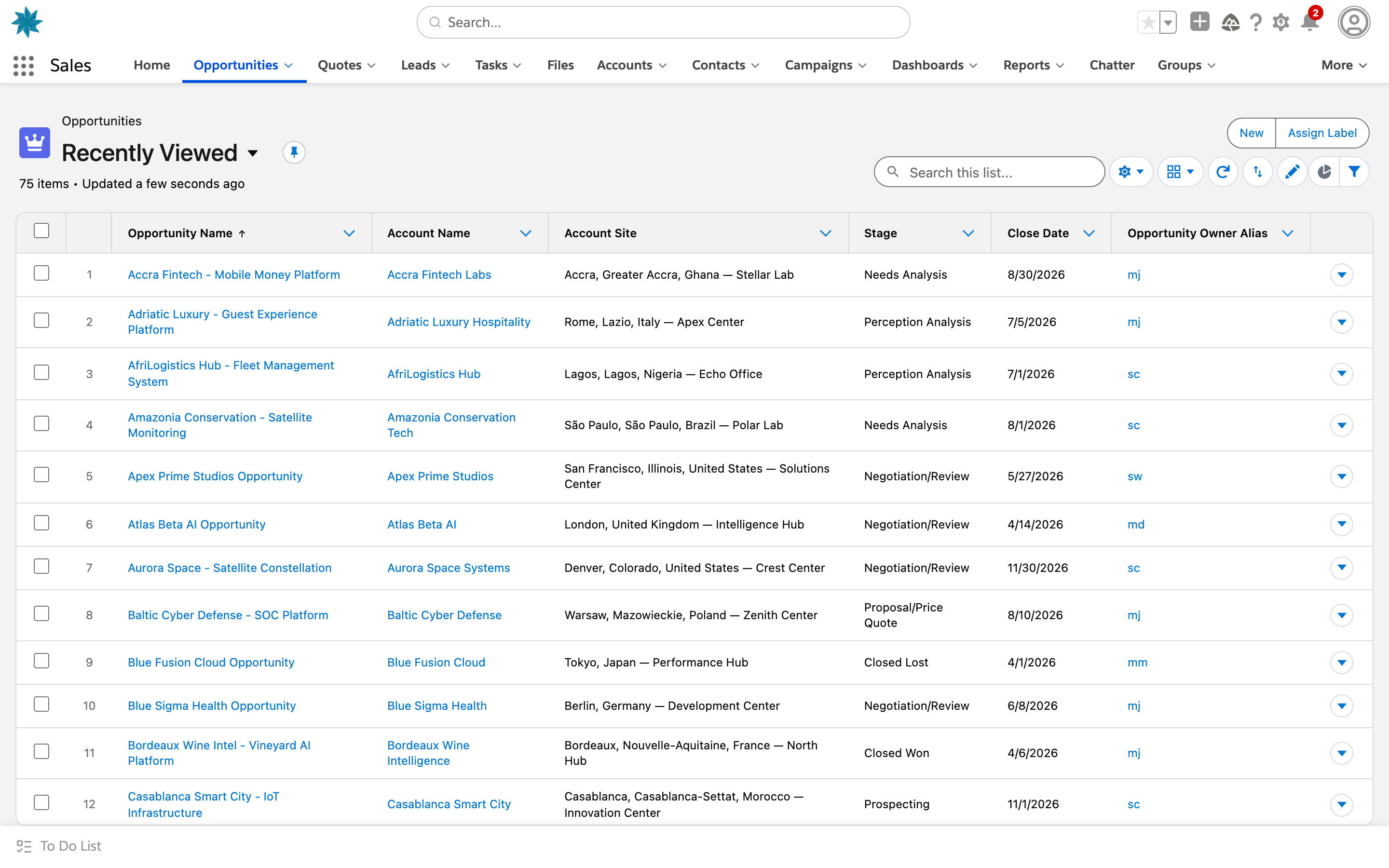
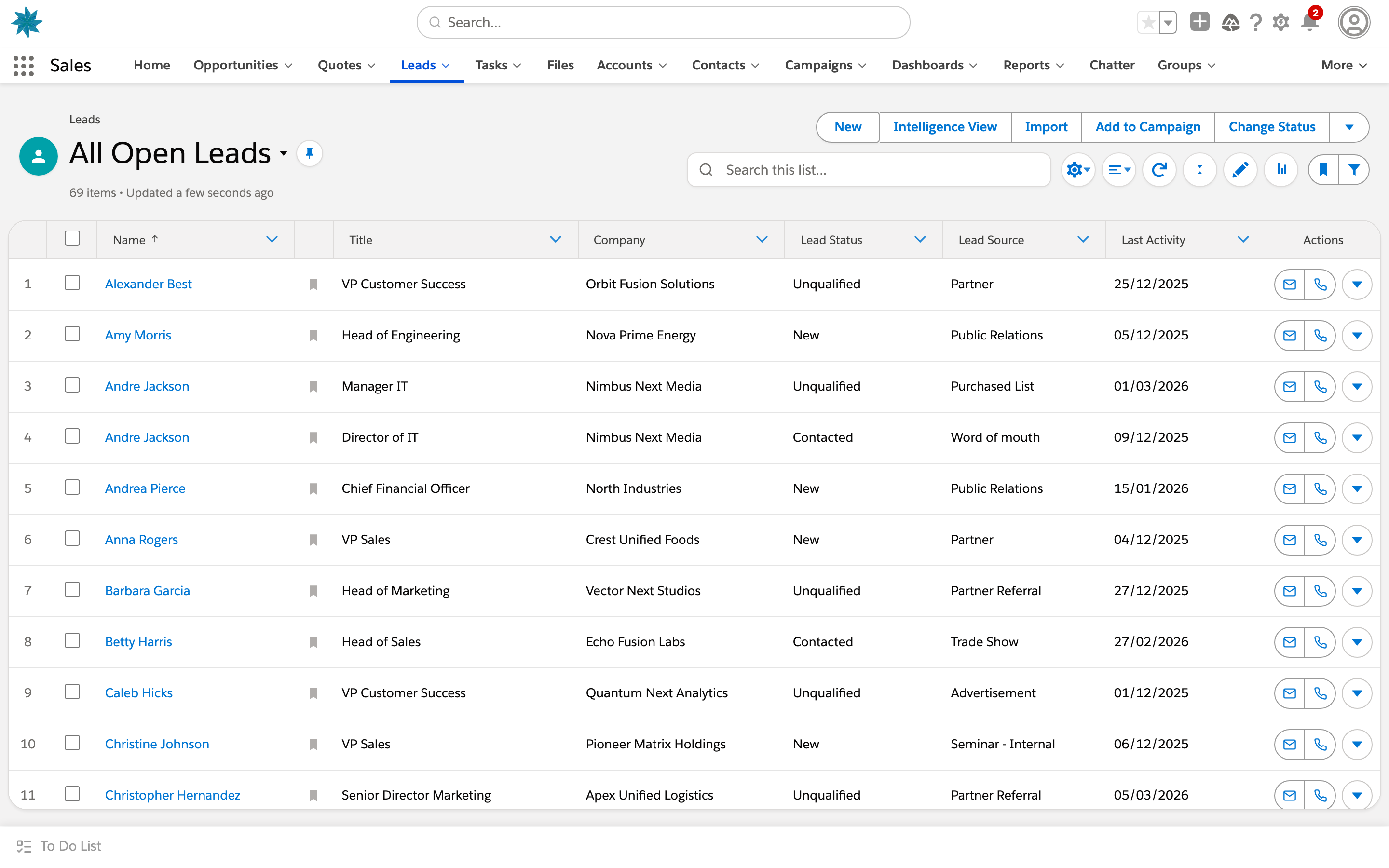
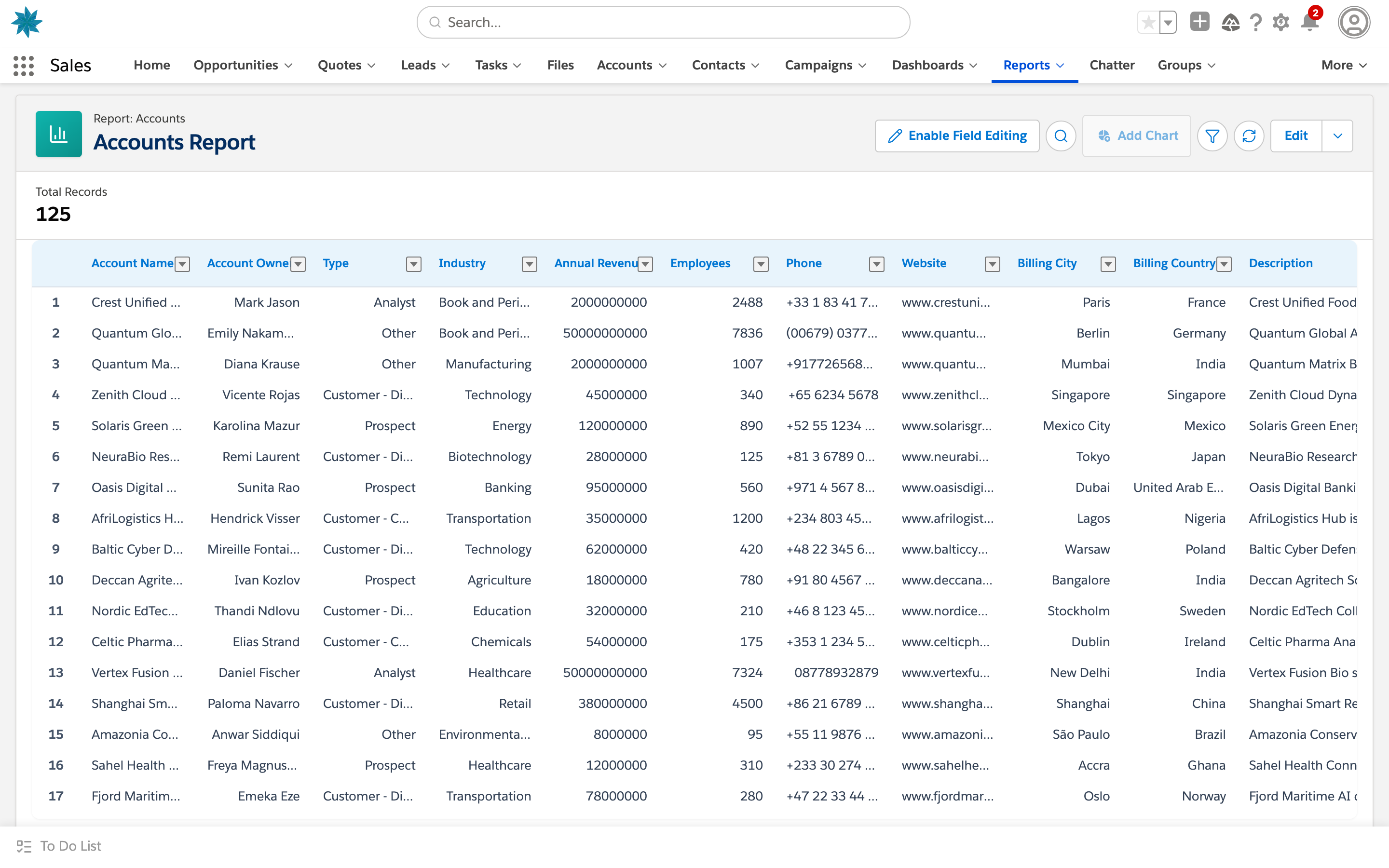
02Environments and domains
Two surfaces: UI gyms are working clones of real apps that an agent drives through the rendered interface; tool-use gyms expose the same products as function-calling APIs. Filter by surface and domain, or search by app.
03A task, end to end
Every task ships with its prompt, the delivered task package and a verifier you can read. This is where an abstract claim about difficulty becomes something you can inspect.
Q1 territory planning
Sales Explorer · SpotHub CRM · LibreOffice Calc
Instruction given to the agent
It is Q1 territory-planning week. Work the jotted candidate list in Q1_Pipeline_Playbook.xlsx: look each candidate up in Sales Explorer, apply the ICP bar from the playbook, and keep the ones that qualify. Build the account list 'Auto Q1 - Targets'. For each qualifier, open a deal on the Sales pipeline in SpotHub, move it to Qualified To Buy, set the amount from the INR price table converted to USD, set the close date, associate the company and a contact, and add an internal note with the deal value. Then fill Q1_Pipeline.xlsx with companies, employees, deal amount, stage probability and weighted pipeline, total it, add a country summary and an HR-hiring column, and insert a combo chart.
The price table is in INR. The USD figure only exists once you apply the 1 USD = 95 INR rate from a separate FX_Rates.xlsx. Skip it and every money figure is 95x too large.
The playbook lists 8 fuzzily-jotted names; 4 are namesake decoys (Crest Matrix Labs vs Crest Health, Polar Future Bio vs Polar Prime Labs). Only 4 clear the ICP bar.
Healthcare, 1,001-10,000 employees, HQ in US or UK, not Texas. The rules are in the file, not the prompt. The model must read and apply them.
The commit date 07/10/2026 is DD/MM (7 Oct 2026). The planning-cycle date 13/12/2025 forces the DD/MM reading.
The real target is the blank Q1_Pipeline.xlsx, not Q1_Pipeline_DRAFT.xlsx or the Q4 and tracker files sitting on the same cluttered desktop.
04How an environment is built
A versioned, persona-first lifecycle, never assembled ad hoc. Each stage pairs people who do the work with automated review, so difficulty is certified, not assumed.
- Synthetic generation: domain experts seed realistic scenarios, a multi-agent system scales them.
- Real enterprise data mapped into the same schema via an adapter layer when production-grade fidelity matters.
- Two-pass validation before anything enters the gym: an agentic critic screens, then a domain expert reviews.
- Every record clears four bars: realism, diversity, consistency and scale.
05Grading you can read, hard to game
High reward has to mean the task was genuinely solved, not that the agent found a shortcut. So grading is deterministic by default, weighted for partial credit, and built to resist reward hacking.
Three verifier roles
The checks that decide whether the task was actually solved. Final-state diffs against gold.
Quality and completeness checks that add partial credit without gating the whole reward.
Did the agent infer the unstated requirements that live in the data, not the prompt?
Three ways to read a score
1.0 only if every core check passes. Closest to a real pass/fail.
Share of all checks that pass. Smooth gradient for RL credit assignment.
Weighted partial credit that gates on core, then rewards the rest. Our default.
Anti reward-hacking
06What you get, and how it plugs in
One environment serves three needs: gold trajectories for SFT, reward signals for RL, and pass rates for eval. Delivered in open formats so it drops into your stack without glue code.
Environments · UI clones + MCP back ends
Versioned, containerized and resettable, with synthetic seed data.
Gold trajectories · for SFT
Expert reference runs of every task, replayable and labeled.
Reward signals · for RL
Deterministic verifiers and weighted, partial-credit scores.
Harness + reports · for eval
Pass rates, traces and measured difficulty, per task and model.
Want the full task set?
We will walk you through a sample end to end, then scope environments, verifiers and task difficulty to your evaluation criteria.